应用背景
有一个应用需要上传一组ID到服务器来查询这些ID所对应的数据,数据库中存储的数据量是7千万,每次上传的ID数量一般都是几百至上千数量级别。
以前的解决方案
- 数据存储在Oracle中,为ID建立了索引;
- 查询时,先将这些上传的ID数据存储到临时表中,然后用表关联的方法来查询。
这样做的优点是减少了查询次数(不用每个ID都查询一次),减少了解析SQL的时间(只需要执行1次查询SQL,但是多了插入数据的SQL处理时间)。
但是这样的设计仍然存在巨大的提升空间,当并发查询的数量增加时,数据库的响应就会很久。虽然建立了索引,但是每个ID查询的时间复杂度仍是O(logn)级别的,那么总的查询时间复杂度就应该是m*O(logn)。不知道Oracle对表关联查询有做了哪些优化,但应该也是改变不了时间复杂度的级别。
解决方法
一遇到读数据库存在瓶颈的问题,首先想到的就是要用内存数据库,用缓存来解决。首选 Redis,因为Redis是一种提供了丰富数据结构的key-value数据库,value可以存储STRING(字符串)、HASH(哈希),LIST(列表),ZSET(有序集)。
首先需要将数据的存储改成 key-value 架构。简单的做法就是一个ID对应一个字符串的 Value。但是一个 ID 可以对应多条数据,而且一条数据内又可以包含多个字段。这时候就需要将这些数据重新组合一下,拼在一起,或者是采用列表、哈希或集合来存储 Value。
Redis内部采用 HashTable(哈希表)来实现key-value的数据结构,是一种空间占用较高的数据结构。而我的应用场景又是ID有几千万规模的,如果按上述方法,使用每个ID作为key,那么内存的消耗将是巨大的。每个key-vaulue结构,Redis本身的维护开销就要80几字节,即便value存储的是纯数字(会使用long类型,占用4个字节),也依然很大,1000万的数据,就要占用快1G内存。
使用两级Hash优化内存
依据官方文档的内存优化方法,以及这篇文章 节约内存:Instagram的Redis实践,建议对ID分段作为key,并使用 hash 来存储第一级 key 的 value,第二级存储较少的数据量(推荐1000),因此第二级的key使用ID的后3位。
为了节约内存,Redis默认使用ziplist(压缩列表)来存储HASH(哈希),LIST(列表),ZSET(有序集)这些数据结构。当某些条件被满足时,自动转换成 hash table(哈希表),linkedlist(双端列表),skiplist(跳表)。
ziplist是用一个数组来实现的双向链表结构,顾名思义,使用ziplist可以减少双向链表的存储空间,主要是节省了链表指针的存储,如果存储指向上一个链表结点和指向下一个链表结点的指针需要8个字节,而转化成存储上一个结点长度和当前结点长度在大多数情况下可以节省很多空间(最好的情况下只需2个字节)。但是每次向链表增加元素都需要重新分配内存。—— 引用自这里的描述
ziplist的详细信息请看 Redis book ziplist 章节
查看 Redis 的 .conf 文件,可以查看到转换条件的设置信息。
1 | # Hashes are encoded using a memory efficient data structure when they have a |
ziplist 查找的时间复杂度是 O(N),但是数据量较少,第二级Hash的查询速度依然在O(1)级别。
对第二级Hash存储的数据再编码
在我的应用场景中每个ID对应的数据可以有很多个字段,这些字段有很多实际上是类型数据,存储的也是ID。为了进一步节约内存,对这些使用数字作为ID的字段,采用base62编码(0-9,A-Z,a-z),这样可以使这些ID的字符长度变短,进一步减少在Redis中第二级hash需要存储的数据量,从而减少Redis占用的内存。
使用Lua脚本来处理批量操作
由于每次查询都上传几百上千个ID,如果对这些ID,都单独调用一次HGET命令,那么一次查询就需要上千次TCP通信,速度很慢。这个时候最好的方法就是一次性将所有的查询都发送到 Redis Server,然后在 Redis Server 处再依次执行HGET命令,这个时候就要用到 Redis 的Pipelining(管道),Lua 脚本(需要 Redis 2.6以上版本)。这两项功能可以用来处理批量操作。由于Lua脚本更简单好用,因此我就直接选用Lua脚本。
Redis Lua 脚本具有原子性,执行过程会锁住 Redis Server,因此 Redis Server 会全部执行完 Lua 脚本里面的所有命令,才会去处理其他命令请求,不用担心并发带来的共享资源读写需要加锁问题。实际上所有的 Redis 命令都是原子的,执行任何 Redis 命令,包括 info,都会锁住 Redis Server。
不过需要注意的是:
为了防止某个脚本执行时间过长导致Redis无法提供服务(比如陷入死循环),Redis提供了lua-time-limit参数限制脚本的最长运行时间,默认为5秒钟(见.conf配置文件)。当脚本运行时间超过这一限制后,Redis将开始接受其他命令但不会执行(以确保脚本的原子性,因为此时脚本并没有被终止),而是会返回”BUSY”错误——引用自这里的描述
遇到这种情况,就需要使用 SCRIPT KILL 命令来终止 Lua 脚本的执行。因此,千万要注意 Lua 脚本不能出现死循环,也不要用来执行费时的操作。
性能分析
测试环境:
- 内存:1333MHz
- CPU:Intel Core i3 2330M 2.2GHz
- 硬盘:三星 SSD
实验基本设置:
- 将7000万数据按照上面描述的方法,使用两级Hash以及对数据再编码,存储到Redis中。
- 模拟数据请求(没有通过HTTP请求,直接函数调用),查询数据,生成响应的JSON数据。
(数据仅供参考,因为未真正结合Web服务器进行测试)
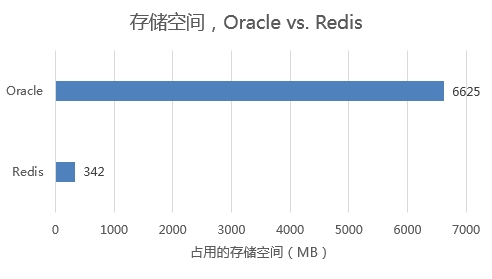
使用上述方法,对Redis的内存优化效果非常好。
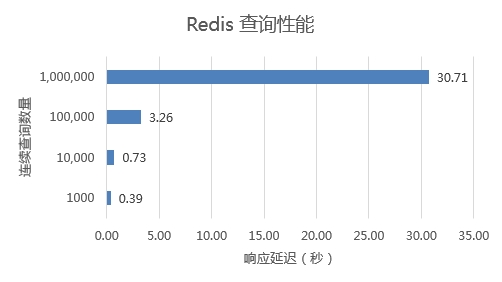
实验设置:
- 模拟每次查询500个ID,分批次连续查询。用于模拟测试并发情况下的查询性能。
响应速度与查询的数据量,几乎是线性相关。30s 的时间就可以处理2000次请求,100W个ID的查询。由于Oracle速度实在太慢,就不做测试了。
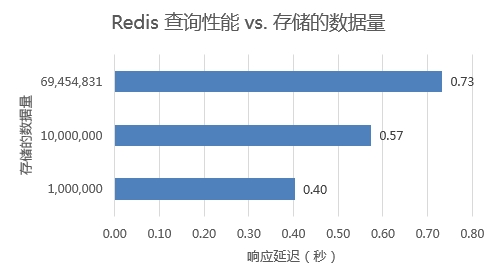
实验设置:
- 连续查询1W个ID,每次500个,分20次。用于测试Redis中存储的数据量对查询性能的影响。
查询速度受存储数据量的影响较小。当存储的数据量较多时,第二级hash存储的数据量就会更多,因此查询时间会有略微的上升,但依然很快。
参考文献
- Redis book(Redis设计与实现)
http://redisbook.readthedocs.org/en/latest/ - Redis 官网 http://redis.io/