defparse_sitemap(self): print('开始抓取sitemap') print('访问 %s' % self.sitemap_url) r = requests.get(self.sitemap_url) data = xmltodict.parse(r.text) self.url_list = [t['loc'] for t in data['urlset']['url']] print('抓取到%s项URL链接' % len(self.url_list))
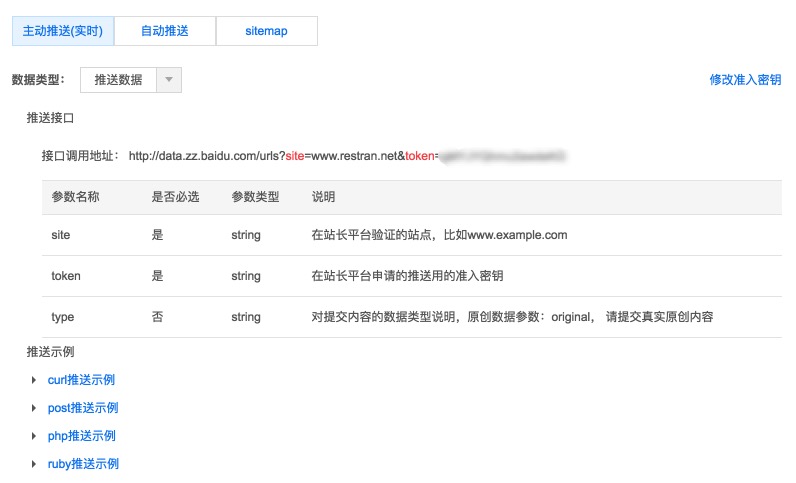
defsubmit(self): url = 'http://data.zz.baidu.com/urls?site=%s&token=%s' % (self.site_domain, self.baidu_token) headers = { 'Content-Type': 'text/plain' } data = '\n'.join(self.url_list) r = requests.post(url, headers=headers, data=data) data = r.json() print('成功推送的url条数: %s' % data.get('success', 0)) print('当天剩余的可推送url条数: %s' % data.get('remain', 0)) not_same_site = data.get('not_same_site', []) not_valid = data.get('not_valid', []) if len(not_same_site) > 0: print('由于不是本站url而未处理的url列表') for t in not_same_site: print(t)
if len(not_valid) > 0: print('不合法的url列表') for t in not_valid: print(t)
defread_sitemap(self): print('开始读取sitemap文件') with open(self.sitemap_file, 'r') as f: self.url_list = [line.strip() for line in f if line.strip() != ''] print('抓取到%s项URL链接' % len(self.url_list))
defsubmit(self): url = 'http://data.zz.baidu.com/urls?site=%s&token=%s' % (self.site_domain, self.baidu_token) headers = { 'Content-Type': 'text/plain' } data = '\n'.join(self.url_list) r = requests.post(url, headers=headers, data=data) data = r.json() print('成功推送的url条数: %s' % data.get('success', 0)) print('当天剩余的可推送url条数: %s' % data.get('remain', 0)) not_same_site = data.get('not_same_site', []) not_valid = data.get('not_valid', []) if len(not_same_site) > 0: print('由于不是本站url而未处理的url列表') for t in not_same_site: print(t)
if len(not_valid) > 0: print('不合法的url列表') for t in not_valid: print(t)